Neural networks (NNs) are an immensely rich and complicated topic. In this chapter, we introduce the simple ideas and concepts behind the most simple architectures of NNs. For more exhaustive treatments on NN idiosyncracies, we refer to the monographs by Haykin (2009), Du & Swamy (2013) and Goodfellow et al. (2016). The latter is available freely online: www
For starters, we briefly comment on the qualification “neural network”. Most experts agree that the term is not very well chosen, as NNs have little to do with how the human brain works (of which we know not that much). This explains why they are often referred to as “artificial neural networks” - we do not use the adjective for notational simplicity. Because we consider it more appropriate, we recall the definition of NNs given by François Chollet: “chains of differentiable, parameterised geometric functions, trained with gradient descent (with gradients obtained via the chain rule)”.
Early references of neural networks in finance are Bansal & Viswanathan (1993) and Eakins et al. (1998). Both have very different goals. In the first one, the authors aim to estimate a nonlinear form for the pricing kernel. In the second one, the purpose is to identify and quantify relationships between institutional investments in stocks and the attributes of the firms (an early contribution towards factor investing). An early review (Burrell & Folarin (1997)) lists financial applications of NNs during the 1990s. More recently, Sezer et al. (2019), Jiang (2020) and Lim & Zohren (2021) survey the attempts to forecast financial time series with deep-learning models, mainly by computer science scholars.
7.1The original perceptron¶
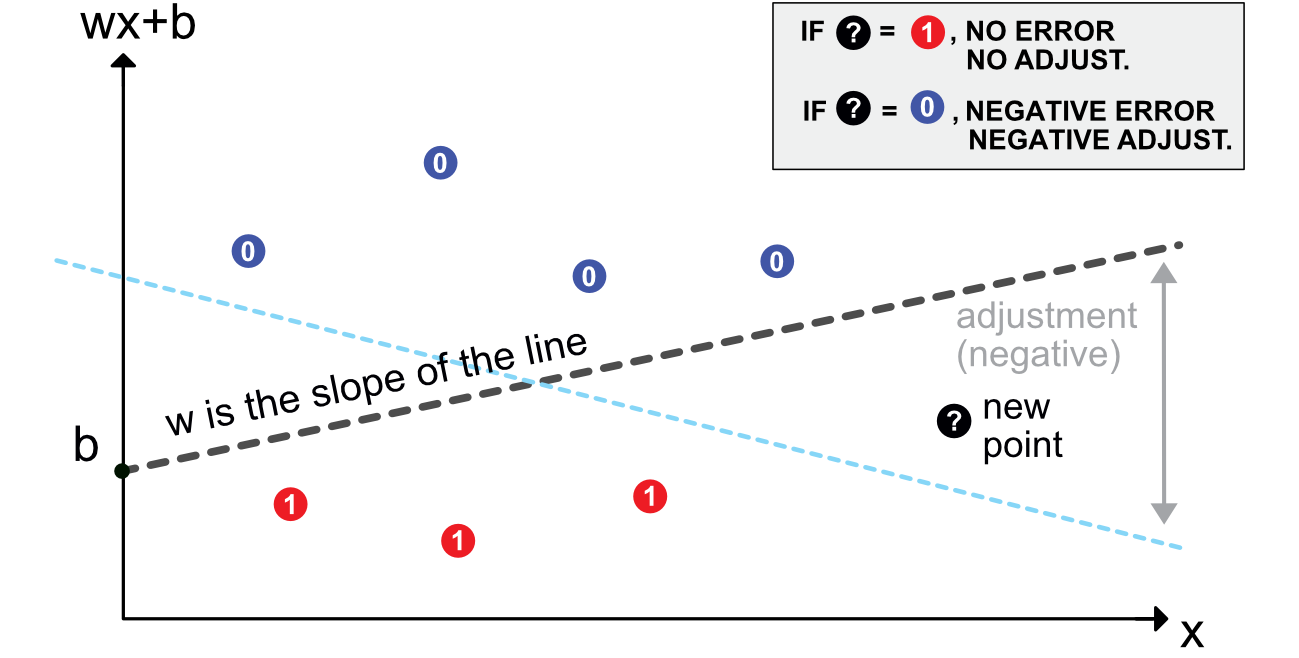
The origins of NNs go back at least to Rosenblatt (1958). Its aim is binary classification. For simplicity, let us assume that the output is = do not invest versus = invest (e.g., derived from return, negative versus positive). Given the current nomenclature, a perceptron can be defined as an activated linear mapping. The model is the following:
The vector of weights scales the variables and the bias shifts the decision barrier.
7.2Multilayer perceptron¶
7.2.1Introduction and notations¶
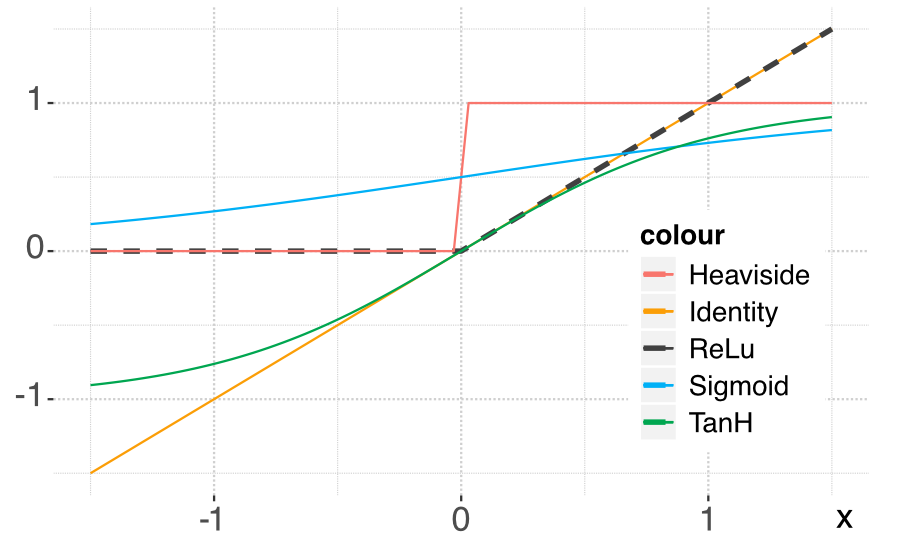
A perceptron can be viewed as a linear model to which is applied a particular function: the Heaviside (step) function. Other choices of functions are naturally possible. In the NN jargon, they are called activation functions. Their purpose is to introduce nonlinearity in otherwise very linear models.
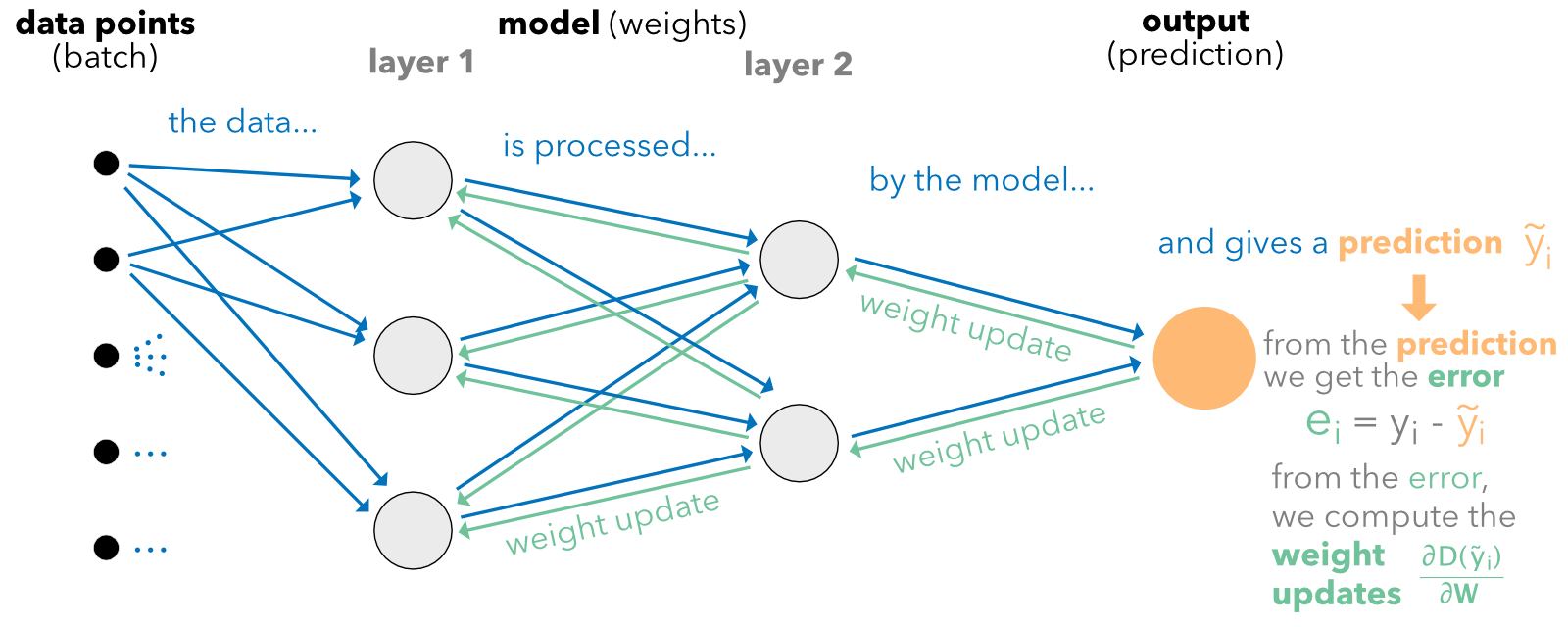
Just like for random forests with trees, the idea behind neural networks is to combine perceptron-like building blocks.
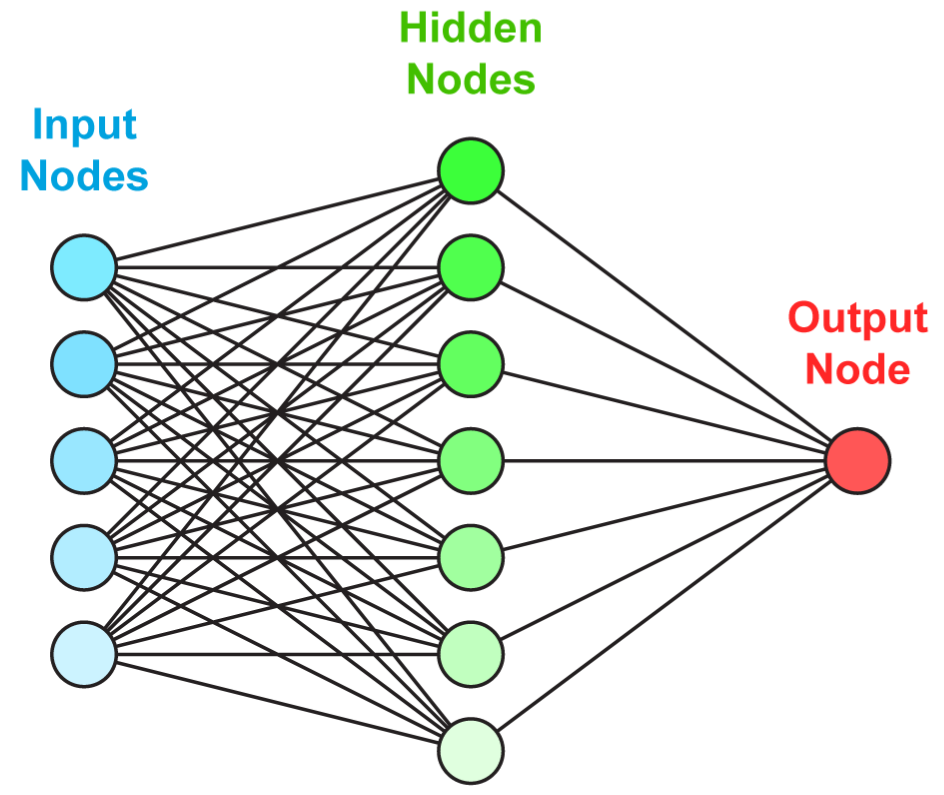
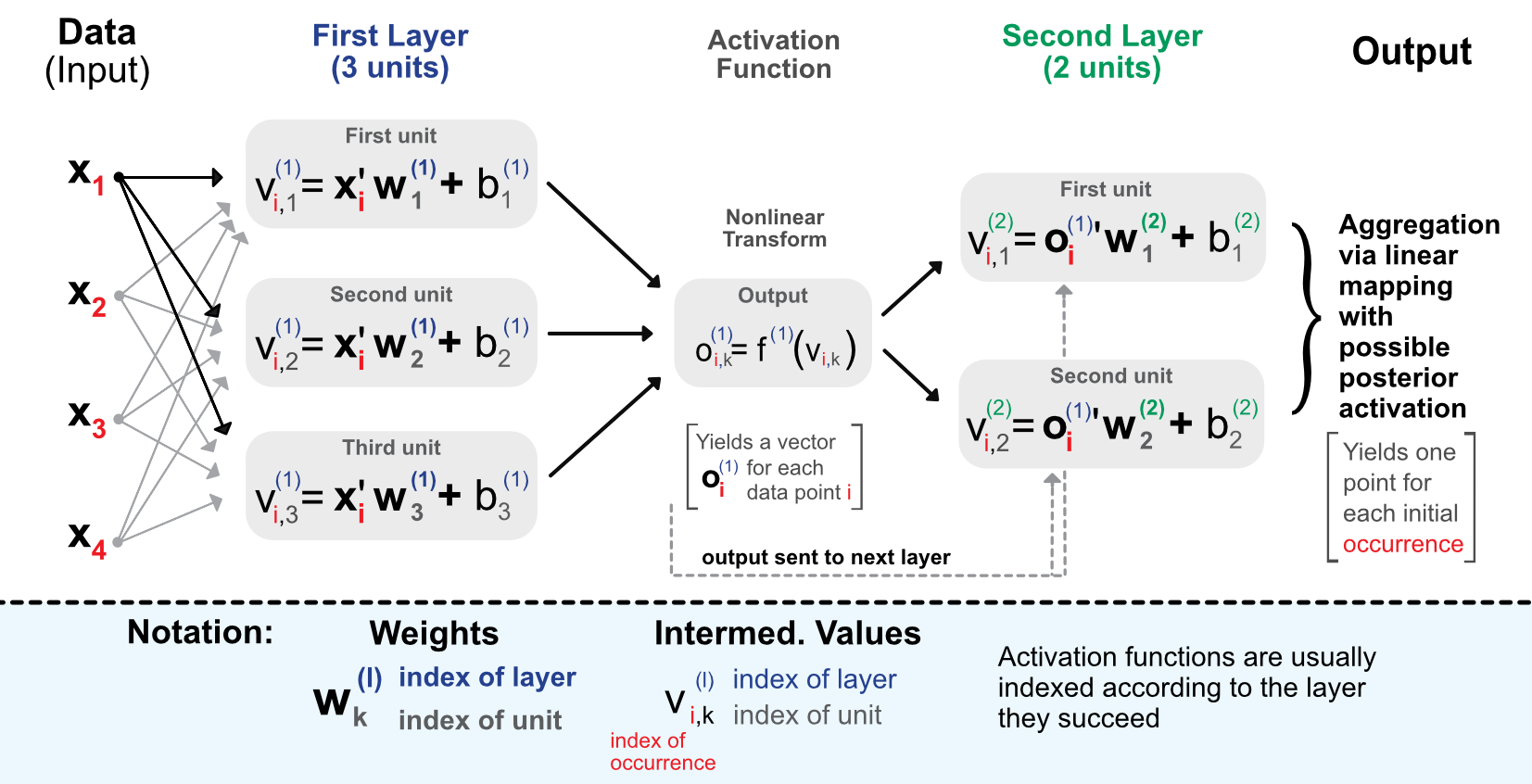
The process is the following. When entering the network, the data goes though the initial linear mapping:
which is then transformed by a non-linear function .
7.2.2Universal approximation¶
One reason neural networks work well is that they are universal approximators. Given any bounded continuous function, there exists a one-layer network that can approximate this function up to arbitrary precision.
7.2.3Learning via back-propagation {#backprop}¶
Just like for tree methods, neural networks are trained by minimizing some loss function subject to some penalization:
The updating of the weights will be performed via gradient descent:
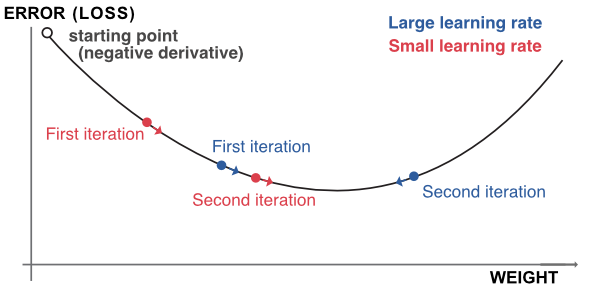
7.2.4Further details on classification {#NNclass}¶
Facing a classification problem, the trick is to use an appropriate activation function at the very end of the network. The most commonly used activation is the so-called softmax function:
The cross-entropy is defined as:
7.3How deep we should go and other practical issues {#howdeep}¶
7.3.1Architectural choices¶
The number of hidden layers in current financial applications rarely exceeds three or four. The number of units per layer is often chosen to follow the geometric pyramid rule:
7.3.2Penalizations and dropout¶
7.4Code samples and comments for vanilla MLP¶
7.4.1Regression example¶
Before we head to the core of the NN, a short stage of data preparation is required.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
plt.style.use('seaborn-v0_8-whitegrid')import os
os.environ["KERAS_BACKEND"] = "jax" # or "torch"
import keras
from keras import layersfrom keras import layers, regularizers, constraints, initializers, callbacks
from data_build import generate_data
data_ml, features, features_short, returns, stock_ids, stock_ids_short = generate_data()
features_short =["Div_yld", "EPS", "Size12m", "Mom_LT", "Ocf", "PB", "Vol_LT"]
separation_date = "2017-01-15"
# Data preparation
data_ml_clean = data_ml.dropna()
training_sample = data_ml_clean[data_ml['date'] <= separation_date]
testing_sample = data_ml_clean[data_ml['date'] > separation_date]
NN_train_features = training_sample[features].values # Training features
NN_train_labels = training_sample['R1M'].values # Training labels
NN_test_features = testing_sample[features].values # Testing features
NN_test_labels = testing_sample['R1M'].values # Testing labelsIn Keras, the training of neural networks is performed through three steps: defining the structure, setting the loss function, and training.
# Define the structure of the network
model = keras.Sequential([
layers.Dense(units=16, activation='relu', input_shape=(NN_train_features.shape[1],)),
layers.Dense(units=8, activation='tanh'),
layers.Dense(units=1) # No activation means linear activation: f(x) = x
])# Model specification
model.compile(
loss='mean_squared_error',
optimizer='rmsprop',
metrics=['mean_absolute_error']
)
model.summary()Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ dense (Dense) │ (None, 16) │ 1,968 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ (None, 8) │ 136 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 1) │ 9 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 2,113 (8.25 KB)
Trainable params: 2,113 (8.25 KB)
Non-trainable params: 0 (0.00 B)
# Train the model
history = model.fit(
NN_train_features, NN_train_labels,
epochs=10, batch_size=512,
validation_data=(NN_test_features, NN_test_labels)
)
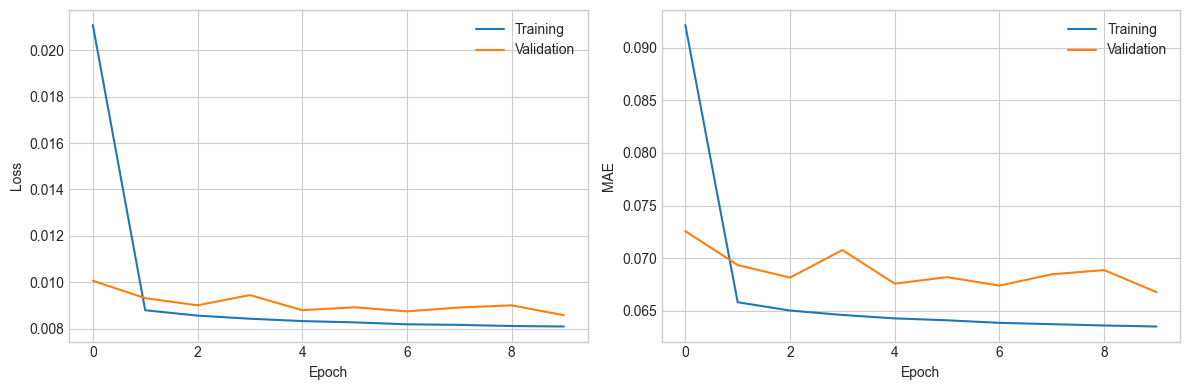
# Plot training history
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(history.history['loss'], label='Training')
axes[0].plot(history.history['val_loss'], label='Validation')
axes[0].set_xlabel('Epoch'); axes[0].set_ylabel('Loss'); axes[0].legend()
axes[1].plot(history.history['mean_absolute_error'], label='Training')
axes[1].plot(history.history['val_mean_absolute_error'], label='Validation')
axes[1].set_xlabel('Epoch'); axes[1].set_ylabel('MAE'); axes[1].legend()
plt.tight_layout(); plt.show()Epoch 1/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - loss: 0.0211 - mean_absolute_error: 0.0922 - val_loss: 0.0101 - val_mean_absolute_error: 0.0726
Epoch 2/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0088 - mean_absolute_error: 0.0658 - val_loss: 0.0093 - val_mean_absolute_error: 0.0693
Epoch 3/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - loss: 0.0086 - mean_absolute_error: 0.0650 - val_loss: 0.0090 - val_mean_absolute_error: 0.0681
Epoch 4/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 897us/step - loss: 0.0084 - mean_absolute_error: 0.0646 - val_loss: 0.0094 - val_mean_absolute_error: 0.0708
Epoch 5/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0083 - mean_absolute_error: 0.0643 - val_loss: 0.0088 - val_mean_absolute_error: 0.0676
Epoch 6/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0083 - mean_absolute_error: 0.0641 - val_loss: 0.0089 - val_mean_absolute_error: 0.0682
Epoch 7/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0082 - mean_absolute_error: 0.0638 - val_loss: 0.0087 - val_mean_absolute_error: 0.0674
Epoch 8/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0082 - mean_absolute_error: 0.0637 - val_loss: 0.0089 - val_mean_absolute_error: 0.0685
Epoch 9/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0081 - mean_absolute_error: 0.0636 - val_loss: 0.0090 - val_mean_absolute_error: 0.0689
Epoch 10/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - loss: 0.0081 - mean_absolute_error: 0.0635 - val_loss: 0.0086 - val_mean_absolute_error: 0.0668
# Predictions and hit ratio
predictions = model.predict(NN_test_features).flatten()
hit_ratio = np.mean(predictions * NN_test_labels > 0)
print(f"Hit ratio: {np.round(hit_ratio, 5)}")2543/2543 ━━━━━━━━━━━━━━━━━━━━ 1s 445us/step
Hit ratio: 0.61639
7.4.2Classification example¶
We pursue our exploration of neural networks with a classification task on the binary label R1M_C.
# One-hot encoding of the labels
NN_train_labels_C = pd.get_dummies(training_sample['R1M_C']).values
NN_test_labels_C = pd.get_dummies(testing_sample['R1M_C']).values# Define the structure with additional features
model_C = keras.Sequential([
layers.Dense(units=16, activation='tanh',
input_shape=(NN_train_features.shape[1],),
kernel_initializer='random_normal',
kernel_constraint=constraints.NonNeg()),
layers.Dropout(rate=0.25),
layers.Dense(units=8, activation='elu',
bias_initializer=initializers.Constant(0.2),
kernel_regularizer=regularizers.l2(0.01)),
layers.Dense(units=2, activation='softmax')
])# Model specification
model_C.compile(
loss='binary_crossentropy',
optimizer=keras.optimizers.Adam(learning_rate=0.005, beta_1=0.9, beta_2=0.95),
metrics=['categorical_accuracy']
)
model_C.summary()Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ dense_3 (Dense) │ (None, 16) │ 1,968 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout (Dropout) │ (None, 16) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_4 (Dense) │ (None, 8) │ 136 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_5 (Dense) │ (None, 2) │ 18 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 2,122 (8.29 KB)
Trainable params: 2,122 (8.29 KB)
Non-trainable params: 0 (0.00 B)
# Train with early stopping
early_stop = callbacks.EarlyStopping(monitor='val_loss', min_delta=0.001, patience=3, verbose=0)
history_C = model_C.fit(
NN_train_features, NN_train_labels_C,
epochs=20, batch_size=512,
validation_data=(NN_test_features, NN_test_labels_C),
verbose=0, callbacks=[early_stop]
)
# Plot
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(history_C.history['loss'], label='Training')
axes[0].plot(history_C.history['val_loss'], label='Validation')
axes[0].set_xlabel('Epoch'); axes[0].set_ylabel('Loss'); axes[0].legend()
axes[1].plot(history_C.history['categorical_accuracy'], label='Training')
axes[1].plot(history_C.history['val_categorical_accuracy'], label='Validation')
axes[1].set_xlabel('Epoch'); axes[1].set_ylabel('Accuracy'); axes[1].legend()
plt.tight_layout(); plt.show()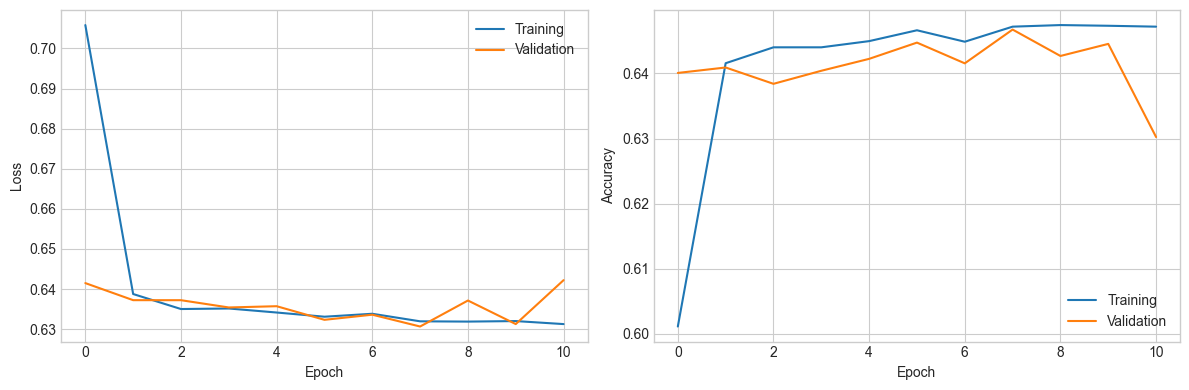
7.4.3Custom losses {#custloss}¶
In Keras, it is possible to define user-specified loss functions.
import keras.ops as ops
def custom_loss(y_true, y_pred):
var_pred = ops.mean((y_pred - ops.mean(y_pred)) * (y_pred - ops.mean(y_pred)))
cov_term = ops.mean((y_true - ops.mean(y_true)) * (y_pred - ops.mean(y_pred)))
return var_pred - 5 * cov_term
model_custom = keras.Sequential([
layers.Dense(units=16, activation='relu', input_shape=(NN_train_features.shape[1],)),
layers.Dense(units=8, activation='sigmoid'),
layers.Dense(units=1)
])
model_custom.compile(loss=custom_loss, optimizer='rmsprop', metrics=['mean_absolute_error'])# Train and evaluate
history_custom = model_custom.fit(
NN_train_features, NN_train_labels,
epochs=10, batch_size=512,
validation_data=(NN_test_features, NN_test_labels)
)
predictions_custom = model_custom.predict(NN_test_features).flatten()
hit_ratio_custom = np.mean(predictions_custom * NN_test_labels > 0)
print(f"Hit ratio: {hit_ratio_custom}")Epoch 1/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - loss: -0.0055 - mean_absolute_error: 1.2541 - val_loss: -0.0075 - val_mean_absolute_error: 1.3321
Epoch 2/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 995us/step - loss: -0.0087 - mean_absolute_error: 1.3368 - val_loss: -0.0086 - val_mean_absolute_error: 1.3151
Epoch 3/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: -0.0097 - mean_absolute_error: 1.3361 - val_loss: -0.0094 - val_mean_absolute_error: 1.3264
Epoch 4/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: -0.0105 - mean_absolute_error: 1.3515 - val_loss: -0.0101 - val_mean_absolute_error: 1.3951
Epoch 5/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - loss: -0.0112 - mean_absolute_error: 1.3952 - val_loss: -0.0106 - val_mean_absolute_error: 1.4458
Epoch 6/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: -0.0117 - mean_absolute_error: 1.4439 - val_loss: -0.0110 - val_mean_absolute_error: 1.4611
Epoch 7/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: -0.0122 - mean_absolute_error: 1.4792 - val_loss: -0.0104 - val_mean_absolute_error: 1.4479
Epoch 8/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: -0.0127 - mean_absolute_error: 1.5270 - val_loss: -0.0111 - val_mean_absolute_error: 1.5543
Epoch 9/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: -0.0130 - mean_absolute_error: 1.5638 - val_loss: -0.0116 - val_mean_absolute_error: 1.5703
Epoch 10/10
257/257 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: -0.0134 - mean_absolute_error: 1.5841 - val_loss: -0.0115 - val_mean_absolute_error: 1.5594
2543/2543 ━━━━━━━━━━━━━━━━━━━━ 1s 195us/step
Hit ratio: 0.4470786323525797
7.5Recurrent networks {#RNN}¶
7.5.1Presentation¶
Multilayer perceptrons are feed-forward networks because the data flows from left to right with no looping in between. For some particular tasks with sequential linkages, it might be useful to keep track of what happened with the previous sample.
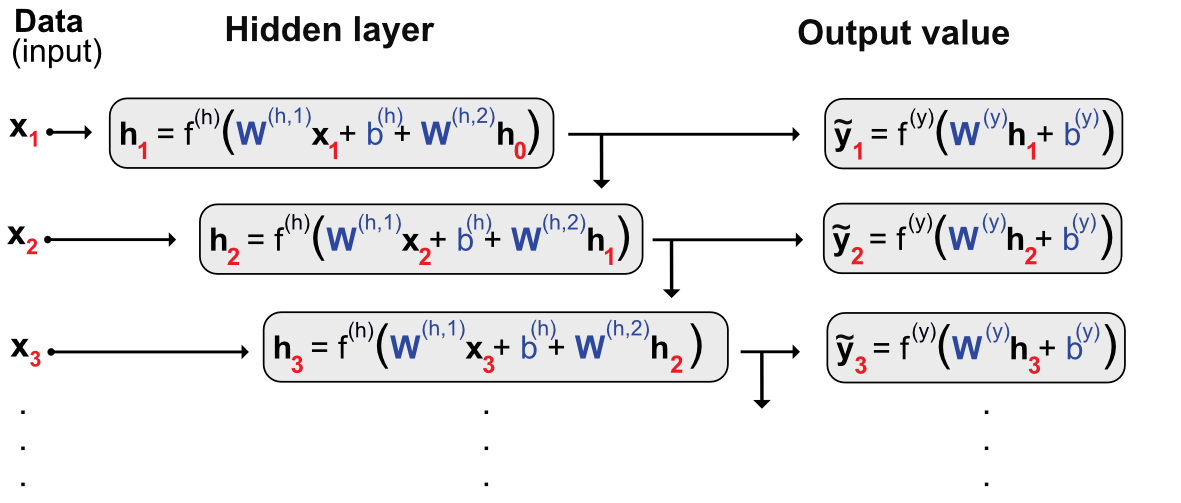
7.5.2Code and results¶
# Dedicated dataset for RNN
data_rnn = data_ml[data_ml['fsym_id'].isin(stock_ids_short)]
training_sample_rnn = data_rnn[data_rnn['date'] < separation_date]
testing_sample_rnn = data_rnn[data_rnn['date'] > separation_date]
nb_stocks = len(stock_ids_short)
nb_feats = len(features)
nb_dates_train = len(training_sample_rnn) // nb_stocks
nb_dates_test = len(testing_sample_rnn) // nb_stocks# Format the data into arrays: (stock, date, feature)
train_features_rnn = training_sample_rnn[features].values.reshape(nb_stocks, nb_dates_train, nb_feats)
test_features_rnn = testing_sample_rnn[features].values.reshape(nb_stocks, nb_dates_test, nb_feats)
train_labels_rnn = training_sample_rnn['R1M'].values.reshape(nb_stocks, nb_dates_train, 1)
test_labels_rnn = testing_sample_rnn['R1M'].values.reshape(nb_stocks, nb_dates_test, 1)# Define the RNN model
model_RNN = keras.Sequential([
layers.GRU(units=16,
#input_batch_size=nb_stocks,
#input_shape=(nb_dates_train, nb_feats),
activation='tanh', return_sequences=True),
layers.Dense(units=1)
])
model_RNN.compile(loss='mean_squared_error', optimizer='rmsprop', metrics=['mean_absolute_error'])# Train the RNN model
history_RNN = model_RNN.fit(
train_features_rnn, train_labels_rnn,
epochs=10, batch_size=nb_stocks, verbose=0
)pred_rnn = model_RNN.predict(test_features_rnn, batch_size=nb_stocks)
hit_ratio_rnn = np.mean(pred_rnn.flatten() * test_labels_rnn.flatten() > 0)
print(f"Hit ratio: {hit_ratio_rnn}")1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step
Hit ratio: 0.48850827111696676
7.6Other common architectures¶
7.6.1Generative adversarial networks {#generative-aversarial-networks}¶
GANs consist in two neural networks: the first one tries to learn and the second one tries to fool the first. and play the following minimax game:
7.6.2Autoencoders {#autoencoders}¶
AEs are a family of neural networks where the label is equal to the input:
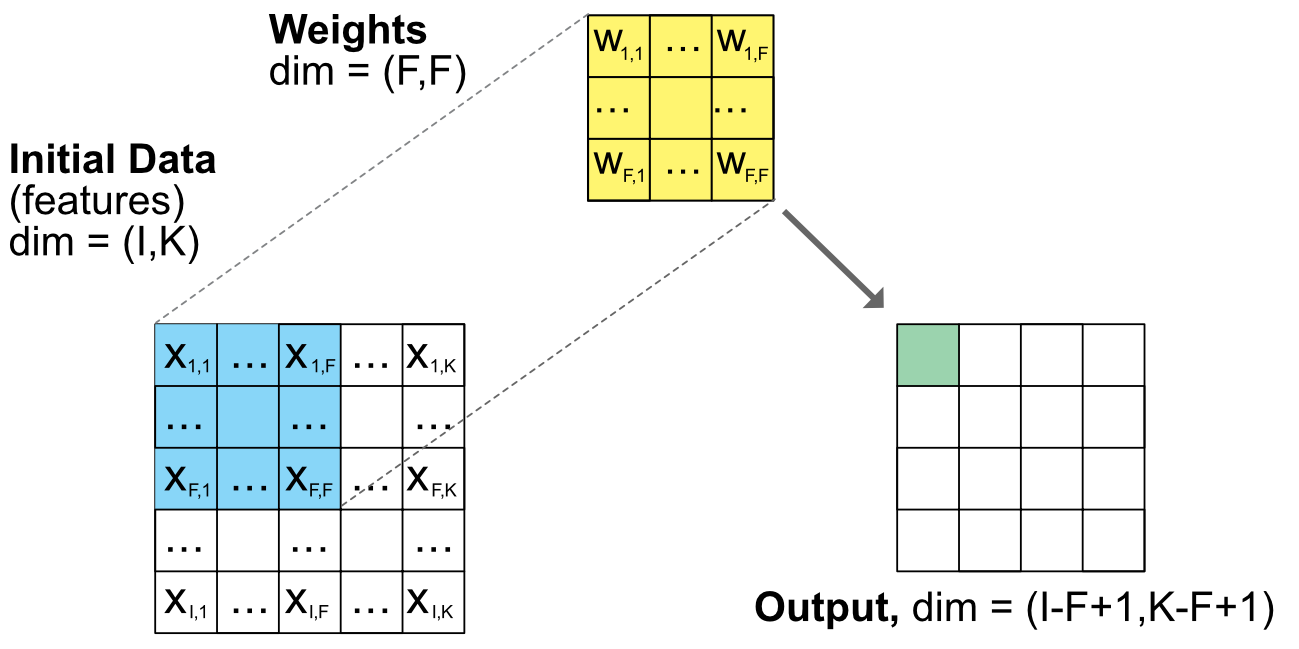
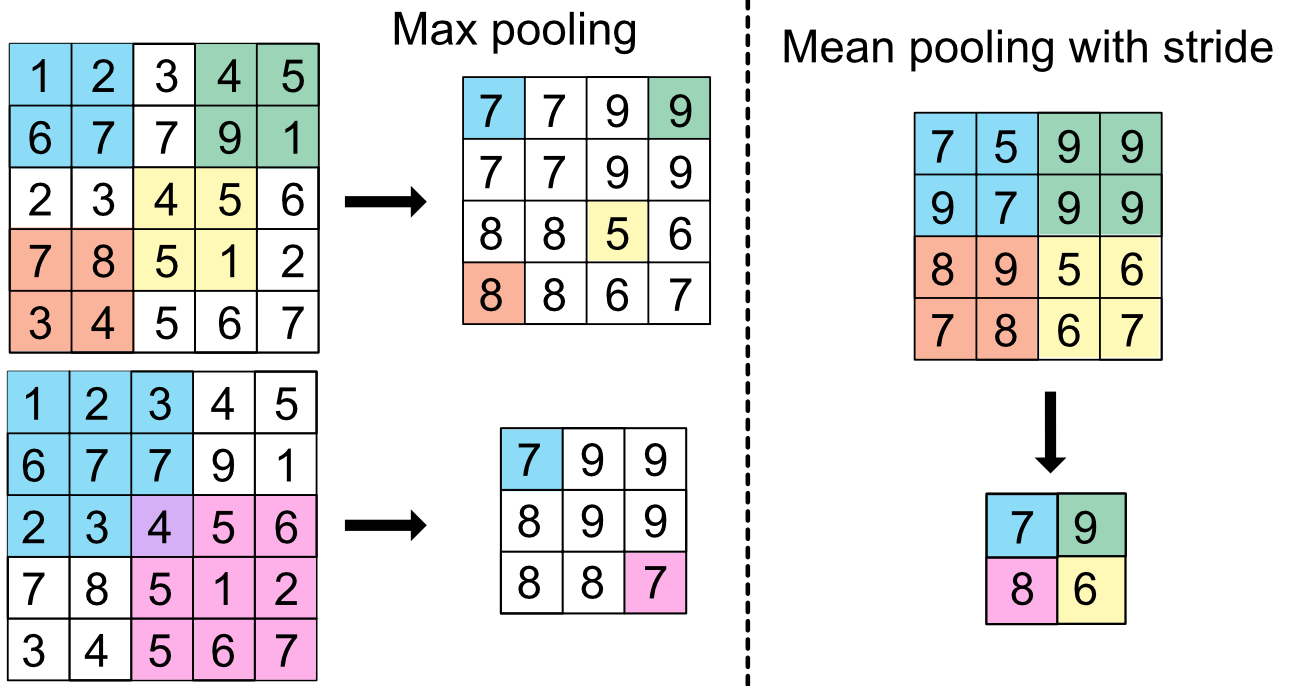
7.6.3A word on convolutional networks {#CNN}¶
CNNs allow to progressively reduce the dimension of a large dataset by keeping local information. The output values are given by:
7.7Coding exercises¶
Code the autoencoder model described in Gu et al. (2021) using the functional API.
Demonstrate the universal approximation of simple NNs by approximating sin(x) over [0,6] with 16 and then 128 units.
- Haykin, S. S. (2009). Neural networks and learning machines. Prentice Hall.
- Du, K.-L., & Swamy, M. N. (2013). Neural networks and statistical learning. Springer Science & Business Media.
- Goodfellow, I., Bengio, Y., Courville, A., & Bengio, Y. (2016). Deep learning. MIT Press Cambridge.
- Chollet, F. (2017). Deep learning with Python. Manning Publications Company.
- Bansal, R., & Viswanathan, S. (1993). No arbitrage and arbitrage pricing: A new approach. Journal of Finance, 48(4), 1231–1262.
- Eakins, S. G., Stansell, S. R., & Buck, J. F. (1998). Analyzing the nature of institutional demand for common stocks. Quarterly Journal Of Business And Economics, 33–48.
- Burrell, P. R., & Folarin, B. O. (1997). The impact of neural networks in finance. Neural Computing & Applications, 6(4), 193–200.
- Sezer, O. B., Gudelek, M. U., & Ozbayoglu, A. M. (2019). Financial Time Series Forecasting with Deep Learning: A Systematic Literature Review: 2005-2019. arXiv Preprint, 1911.13288.
- Jiang, W. (2020). Applications of deep learning in stock market prediction: recent progress. arXiv Preprint, 2003.01859.
- Lim, B., & Zohren, S. (2021). Time Series Forecasting With Deep Learning: A Survey. Philosophical Transactions Of The Royal Society A, 379(2194), 20200209.
- Rosenblatt, F. (1958). The perceptron: a probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386.
- Gu, S., Kelly, B. T., & Xiu, D. (2021). Autoencoder Asset Pricing Models. Journal of Econometrics, 222(1), 429–450.